Wie Sie bereits wissen, macht unser KV² Plugin Ephesoft selbstlernend. Es sorgt dafür, dass Erkennungs- und Extraktionsregeln für Dokumente sich kontinuierlich verbessern und aktualisieren. Die folgenden Techniken werden auf Basis von vorheriger Transformation in ein OCR Dokument angewandt.
Durch maschinelles Lernen ist unser PlugIn in der Lage…
- …die Dokumente über #TF-IDF zu analysieren und zu identifizieren
- …Extraktionsregeln zu synchronisieren und
- …neue Extraktionsregeln durch einmalige menschliche Hilfe einzufügen und anschließend selbstständig anzuwenden
Wir möchten in diesem Blog gerne auf den Begriff TF-IDF näher eingehen und Ihnen diesen in der Theorie erklären, sodass die Erfolge in der Praxis besser zu verstehen sind. Wie oben bereits beschrieben geht es hierbei um die Identifizierung, Klassifizierung und Analyse von Dokumenten. TF-IDF (der Begriff wird in der unten stehenden Formel erläutert) gibt jedem Dokument einen Identifikator.

Dieser Identifikator beschreibt das Maß für die Originalität eines gewissen Wortes, indem die Anzahl des Vorkommens eines Wortes in einem Dokument mit der Anzahl der Dokumente, in denen das Wort vorkommt, verglichen wird.
Klingt kompliziert? Vereinfacht gesagt, TF-IDF misst die Ähnlichkeit von Dokumenten.
D.h. die Häufigkeit eines Wortes (TF) wird in unserem PlugIn mit der Inversen Dokumentenhäufigkeit (IDF) verglichen.
Danach ergibt sich folgende Graphik:
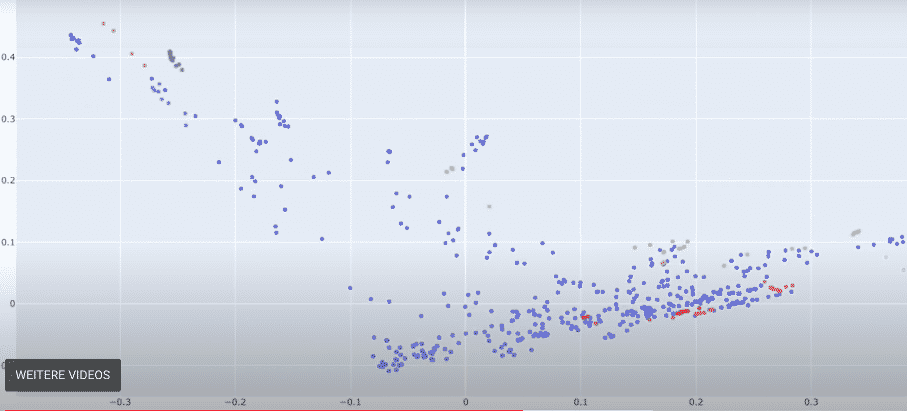
Die einzelnen Punkte auf dieser Graphik stellen Begriffskennzeichen dar. Das interessante ist die Clusterbildung hinter diesen Punkten.
Die Cluster geben Auskunft darüber, welche Rechnungen von welchen Lieferanten ausreichend ähnlich sind.
Somit sind wir in der Lage Extraktionsregeln gewissen Lieferanten zuzuordnen, sodass nicht für jeden Lieferanten ein neues Regel- und somit Extraktionstemplate erstellt werden muss.
Jetzt wissen Sie mehr über die TF-IDF Funktion unseres PlugIns. Im nächsten Blog tauchen wir noch tiefer ein!




