Es ist kein großes Geheimnis, dass Unternehmen aller Branchen ihren Dokumentenmanagement-Prozess digitalisieren und automatisieren müssen. Unser Ziel ist es daher, alle Rechnungsdaten zu nahezu 100 % automatisch zu extrahieren!

Unsere neue Lösung: Fellow²KV
Die Realität ist, dass Unternehmen an einem Tag, in einem Monat oder sogar in einem Jahr unzählige Rechnungen erhalten, aber nicht einmal 80 % davon werden richtig extrahiert. Eine Dokumentenmanagement-Software zu haben, ist bereits ein großer Schritt, um Kosten, Zeit und Ressourcen zu sparen. Aber, wie alles im Leben, können Änderungen und Verbesserungen vorgenommen werden.
Die Fellow Consulting AG hat eine neue Version namens Fellow²KV entwickelt. Dieses Plugin für maschinelles Lernen ist in der Lage, die Software Ephesoft Transact zu trainieren, um die richtigen Daten während Ihres Digitalisierungsprozesses zu identifizieren. Es kann die folgenden drei Funktionen auf einmal ausführen:
- Analyse von Dokumenten mittels TF-IDF.
- Synchronisierung der Extraktionsregeln.
- Anlernen neuer Extraktionsregeln durch einmalige menschliche Unterstützung.

Wie funktioniert es?
Mit unserem Fellow²KV können wir die Genauigkeit der Ephesoft Engine verbessern, indem wir sie mit unserem Cloud-basierten Extraktions-Repository befüllen. Jedes Mal, wenn Rechnungen validiert und dann exportiert werden, werden die neuen Extraktionsregeln in demselben Repository gespeichert und erneut aktualisiert.
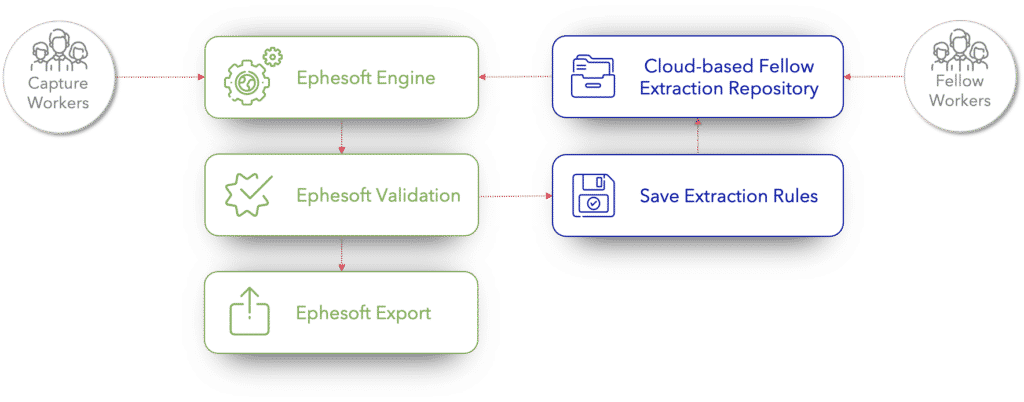
Um diese Regeln auf die spezifischen Rechnungslayouts anwenden zu können, müssen wir die Rechnungen mit bestimmten Begriffen oder genauer gesagt mit einem Identifikator abgleichen. Dies geschieht mit Hilfe der TF-IDF.
TF-IDF gewichtet die Häufigkeit eines Terms (TF) und seine inverse Dokumentenhäufigkeit (IDF). Jedes Wort oder jeder Begriff, der im Text vorkommt, hat seinen jeweiligen TF- und IDF-Score. Dies würde mehr oder weniger so aussehen:
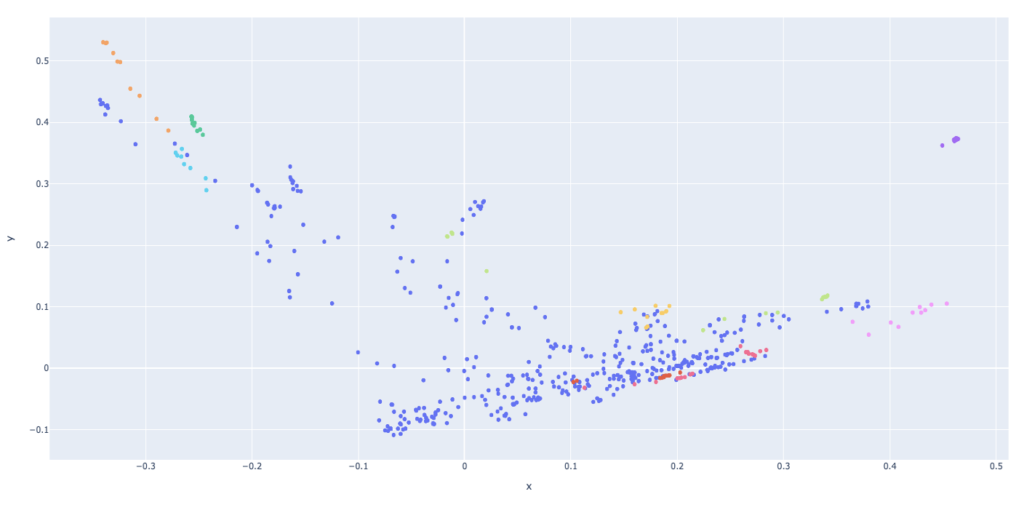
Jeder Punkt zeigt eine andere Begriffskennung, aber was wir wirklich wollen, ist, die Punkte nahe beieinander zu gruppieren, um einen Cluster zu erstellen. Dieser Cluster stellt einfach ein Rechnungslayout dar, das für verschiedene Lieferanten verwendet werden kann. Dieses K-Means-Clustering würde wie folgt aussehen:
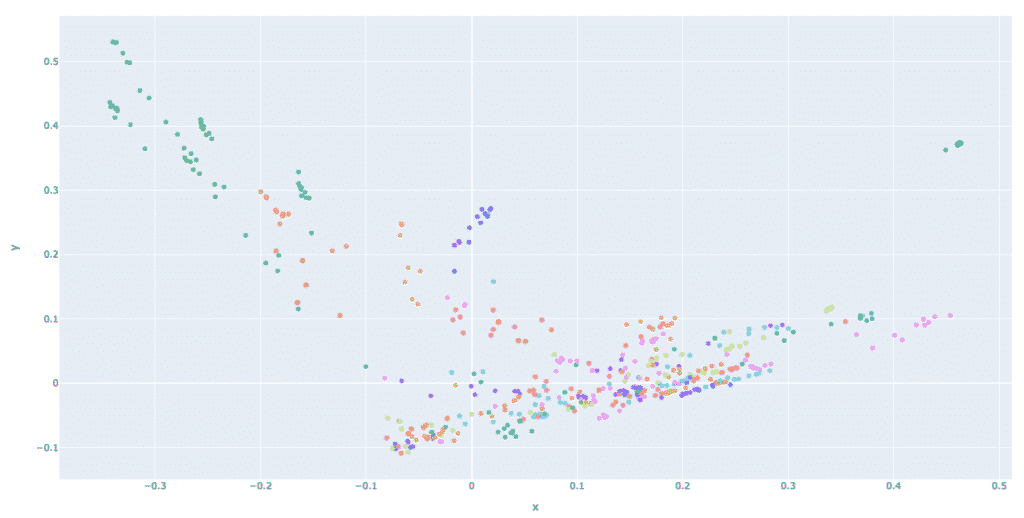
Nun stellen Sie sich vor, diesen Vorgang eine Million Mal zu wiederholen und das Fellow²KV-Repository mit immer mehr Daten zu füllen. Nahezu 100 % genaue Extraktion ist sicherlich machbar, meinen Sie nicht? Deshalb können Sie es vergessen, die Ephesoft Engine 4 bis 6 Monate lang zu trainieren, mit Fellow²KV können Sie vom ersten Tag an beginnen!




