To profit from the artificial intelligence of our PlugIn, we need to train this intelligence in the first place. In this blog article, we will show you how.
In addition, you will learn how we can optimize your invoicing process for example by using machine learning.
a quick reminder:
The FellowKV² Plugin solution is a cloud-based rule-repository. It grants the customer access to a pool of extraction rules to read data out of documents, in particular invoices.
For the PlugIn to know which fields to extract and where to find the metadata, we train the AI of the PlugIn. This can be the case, whenever your company adds a new supplier or vendor for example.
Even with the first upload of your document, our repository of rules is responsible for our PlugIn to already detect most of the data.
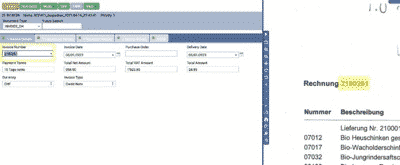
We read the non-extracted data manually by clicking on the document. No IT -Ressource or programming is needed here.
As mentioned before, with this process you validate the document ant the AI. With every one-time human assistance validating and exporting the new document type, new extraction rules are deposited in the repository. For the next Invoices of the same type, all data will be extracted. The plugin will recognize values were missing in the first run.
This process is performed by all users, when necessary, and continuously improvess the central rule repository.
To learn more about our PlugIn head over to our website. Here you can also find a video for further explanation of the FellowKV² PlugIn.
If you haven’t read our last blog about the usage of our TF-IDF model, please have a look here. In this blog we shed more light on the mathematical side of artificial intelligence.
See you soon!





