Apache Spark and Databricks are getting more and more popular. 2018 and 2019 ist was the most important language zu learn. In our next days we go throw the most important steps about Azure Databricks and Apache Spark.
So first why is Apache Spark so popular? With Apache Spark you can run programs 100 times faster than any other technology.
If you want to start quickly without setup any enviroment you can use Google Colab and best it is complete for free.
What is Apache Spark?
The Spark is a project of Apache, popularly known as “lightning fast cluster computing”. Spark is an open-source framework for the processing of large datasets. It is the most active Apache project of the present time. Spark is written in Scala and provides APIs in Python, Scala, Java, and R.
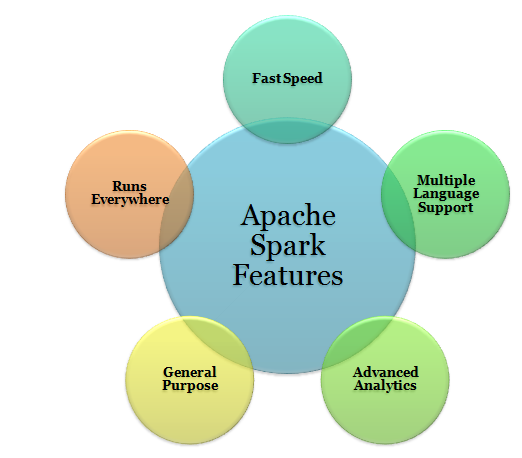
The most important feature of Apache Spark is its in-memory cluster computing that is responsible to increase the speed of data processing. Spark is known to provide a more general and faster data processing platform. It helps you run programs comparatively faster than Hadoop i.e. 100 times faster in memory and 10 times faster even on the disk.
Worth mention, contradicting a common misbelief, Apache Spark cannot be considered as a modified version of Apache Hadoop. Spark has its own cluster management, so it’s not dependent on Hadoop. But Spark is just a way to implement Spark. Spark uses Hadoop only for storage purpose.
You need to have Python3 up and running. If you want to use Google Colab here you need to run the commands with ! first like: !apt-get updat
Multiple Language Support
Apache Spark supports multiple languages; it provides APIs written in Scala, Java, Python or R. It allows users to write applications in different languages. Note that Spark comes up with 80 high-level operators for interactive querying.
Advanced Analytics
Apache Spark is known to support ‘Map’ and ‘Reduce’ that has been mentioned earlier. But along with MapReduce, it supports Streaming data, SQL queries, Graph algorithms, and Machine learning. Thus, Apache Spark is a great mean of performing advanced analytics.
General Purpose
The spark is a powered by the plethora of libraries for machine learning i.e. MLlib, DataFrames, and SQL along with Spark Streaming and GraphX. One is allowed to use a combination of these libraries coherently in an application. The feature of combining streaming, SQL, and complex analytics, and using in the same application makes Spark a general-purpose framework.
Runs Everywhere
Spark can run on multiple platforms without affecting the processing speed. It can run on Hadoop, Kubernetes, Mesos, Standalone, and even in the Cloud. Also, Spark can have access to different sources of data such as HDFS, HBase, Cassandra, Tachyon, and S3.
apt-get update
apt-get install openjdk-8-jdk-headless -qq > /dev/null
wget -q https://archive.apache.org/dist/spark/spark-2.3.1/spark-2.3.1-bin-hadoop2.7.tgz
tar xf spark-2.3.1-bin-hadoop2.7.tgz
pip install -q findsparkimport os
os.environ["JAVA_HOME"] = "/usr/lib/jvm/java-8-openjdk-amd64"
os.environ["SPARK_HOME"] = "https://www.fellow-consulting.com/content/spark-2.3.1-bin-hadoop2.7"
import findspark
findspark.init()
from pyspark import SparkContext
sc = SparkContext.getOrCreate()
Daniel Jordan
Fellow Consulting AG
If you have any question please contact me on this channels:









